Технология Hyper-Threading – первый шаг к многоядерности
Анонсированная в 2002 году компанией Intel технология Hyper-Threading – пример многопоточной обработки команд. Данная технология является чем-то средним между многопоточной обработкой, реализованной в мультипроцессорных системах, и параллелизмом на уровне инструкций, реализованном в однопроцессорных системах. Фактически технология Hyper-Threading позволяет организовать два логических процессора в одном физическом. Таким образом, с точки зрения операционной системы и запущенного приложения в системе существует два процессора, что даёт возможность распределять загрузку задач между ними точно так же, как при SMP-мультипроцессорной конфигурации.
Посредством реализованного в технологии Hyper-Threading принципа параллельности можно обрабатывать инструкции в параллельном (а не в последовательном) режиме, то есть для обработки все инструкции разделяются на два параллельных потока. Это позволяет одновременно обрабатывать два различных приложения или два различных потока одного приложения и тем самым увеличить IPC процессора, что сказывается на росте его производительности.
В конструктивном плане процессор с поддержкой технологии Hyper-Threading состоит из двух логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architecture State, AS), а значит, две параллельно исполняемые задачи работают со своими собственными независимыми регистрами и прерываниями, но при этом используют одни и те же ресурсы процессора для выполнения своих задач. После активации каждый из логических процессоров может самостоятельно и независимо от другого процессора выполнять свою задачу, обрабатывать прерывания либо блокироваться. Таким образом, от реальной двухпроцессорной конфигурации новая технология отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну и ту же системную шину. Использование двух логических процессоров позволяет усилить процесс параллелизма на уровне потока, реализованный в современных операционных системах и высокоэффективных приложениях.
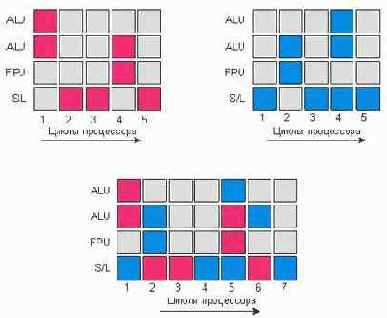
Команды от обоих исполняемых параллельно потоков одновременно посылаются для обработки ядру процессора. Используя технологию out-of-order (исполнение командных инструкций не в порядке их поступления), ядро процессора тоже способно параллельно обрабатывать оба потока за счёт использования нескольких исполнительных модулей. Идея технологии Hyper-Threading тесно связана с микроархитектурой NetBurst процессора Pentium 4 и является в каком-то смысле её логическим продолжением. Микроархитектура Intel NetBurst позволяет получить максимальный выигрыш в производительности при выполнении одиночного потока инструкций, то есть при выполнении одной задачи. Однако даже в случае специальной оптимизации программы не все исполнительные модули процессора оказываются задействованными на протяжении каждого тактового цикла. В среднем при выполнении кода, типичного для набора команд IA-32, реально используется только 35% исполнительных ресурсов процессора, а 65% исполнительных ресурсов процессора простаивают, что означает неэффективное использование возможностей процессора. Было бы вполне логично реализовать работу процессора таким образом, чтобы в каждом тактовом цикле максимально использовать его возможности. Именно эту идею и реализует технология Hyper-Threading, подключая незадействованные ресурсы процессора к выполнению параллельной задачи. Поясним всё вышесказанное на примере. Представьте себе гипотетический процессор, в котором имеется четыре исполнительных блока: два блока для работы с целыми числами (арифметико-логическое устройство, ALU), блок для работы с числами с плавающей точкой (FPU) и блок для записи и чтения данных из памяти (Store/Load, S/L). Пусть, кроме того, каждая операция осуществляется за один такт процессора. Далее предположим, что выполняется программа, состоящая из трёх инструкций: первые две — арифметические действия с целыми числами, а последняя — сохранение результата. В этом случае вся программа будет выполнена за два такта процессора: в первом такте задействуются два блока ALU процессора (красный квадрат на рис. 1), во втором — блок записи и чтения данных из памяти S/L.
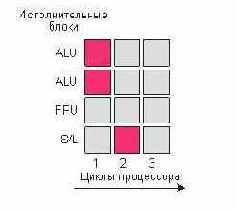
Реализация параллелизма на уровне инструкций (Instruction Level Parallelism, ILP) В современных приложениях в любой момент времени, как правило, выполняется не одна, а несколько задач или несколько потоков (threads) одной задачи, называемых также нитями. Давайте посмотрим, как будет вести себя наш гипотетический процессор при выполнении двух разных потоков задач (рис. 2). Красные квадраты соответствуют использованию исполнительных блоков процессора одного потока, а синие квадраты — другого. Если бы оба потока исполнялись изолированно, то для выполнения первого и второго потока потребовалось бы по пять тактов процессора. При одновременном исполнении обоих потоков процессор будет постоянно переключаться между обоими потоками, следовательно, за один такт процессора выполняются только инструкции какого-либо одного из потоков. Для исполнения обоих потоков всего потребуется десять процессорных тактов.
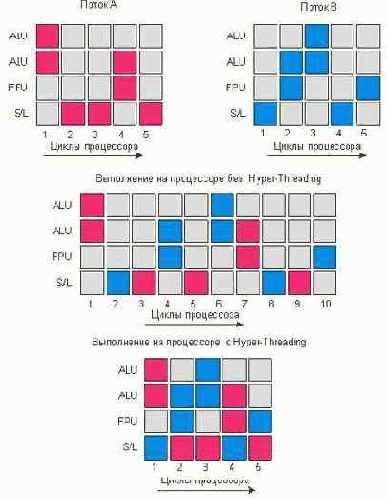
Пусть имеется два потока команд, каждый из которых по отдельности выполняется за пять тактов процессора. Без использования технологии Hyper-Threading для выполнения обоих потоков потребовалось бы десять тактов процессора. А теперь выясним, что произойдет при использовании технологии Hyper-Threading (рис. 3). На первом такте процессора каждый из потоков задействует различные блоки процессора, поэтому выполнение инструкций легко совместить. Аналогичное положение вещей наличествует и на втором такте, а вот на третьем такте инструкции обоих потоков пытаются задействовать один и тот же исполнительный блок процессора, а именно блок S/L. В результате возникает конфликтная ситуация, и один из потоков должен ждать освобождения требуемого ресурса процессора. То же самое происходит и на пятом такте. В итоге оба потока выполняются не за пять тактов (как в идеале), а за семь.